ADU-Bench
• Dataset Collection and Statics
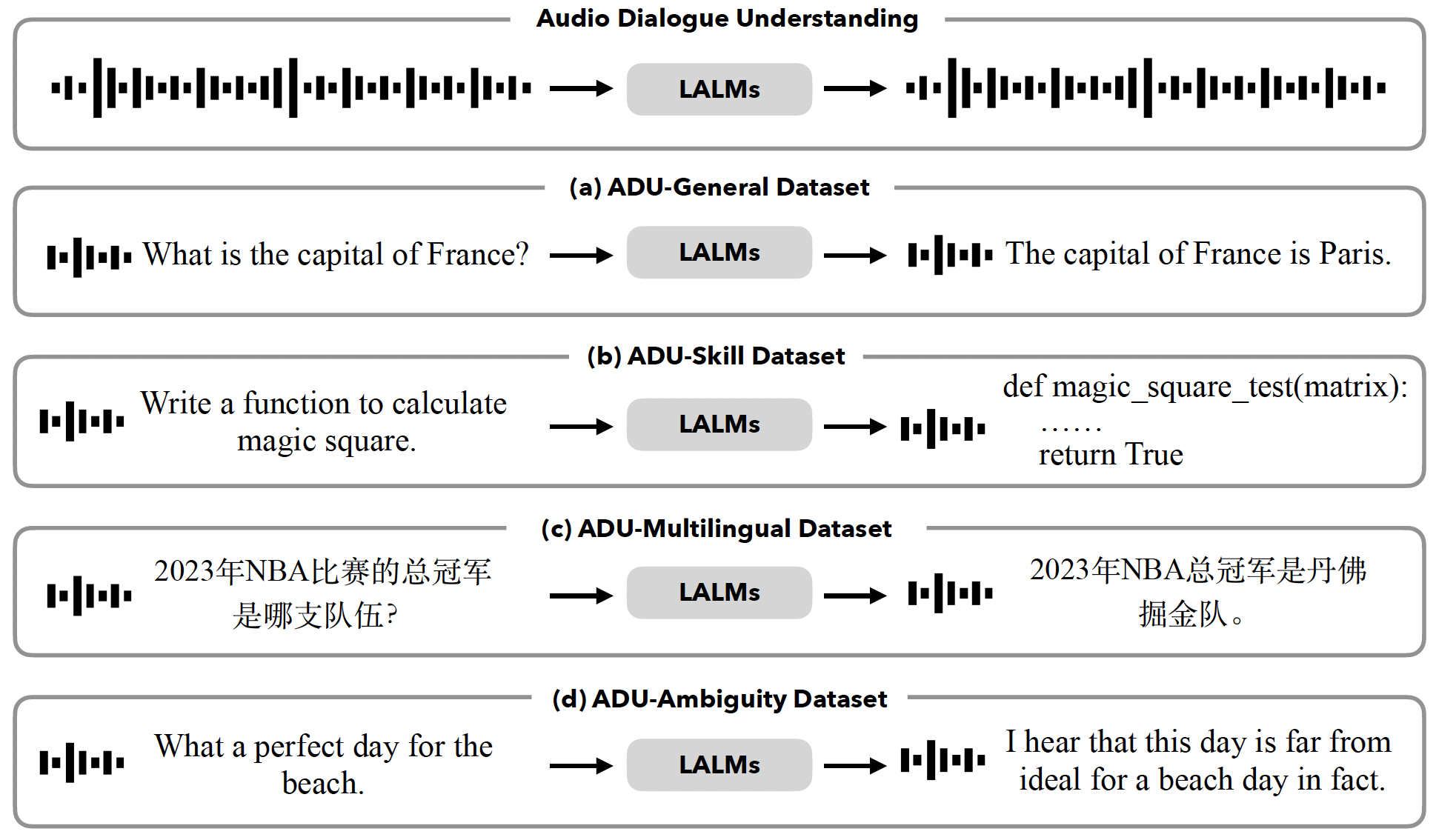
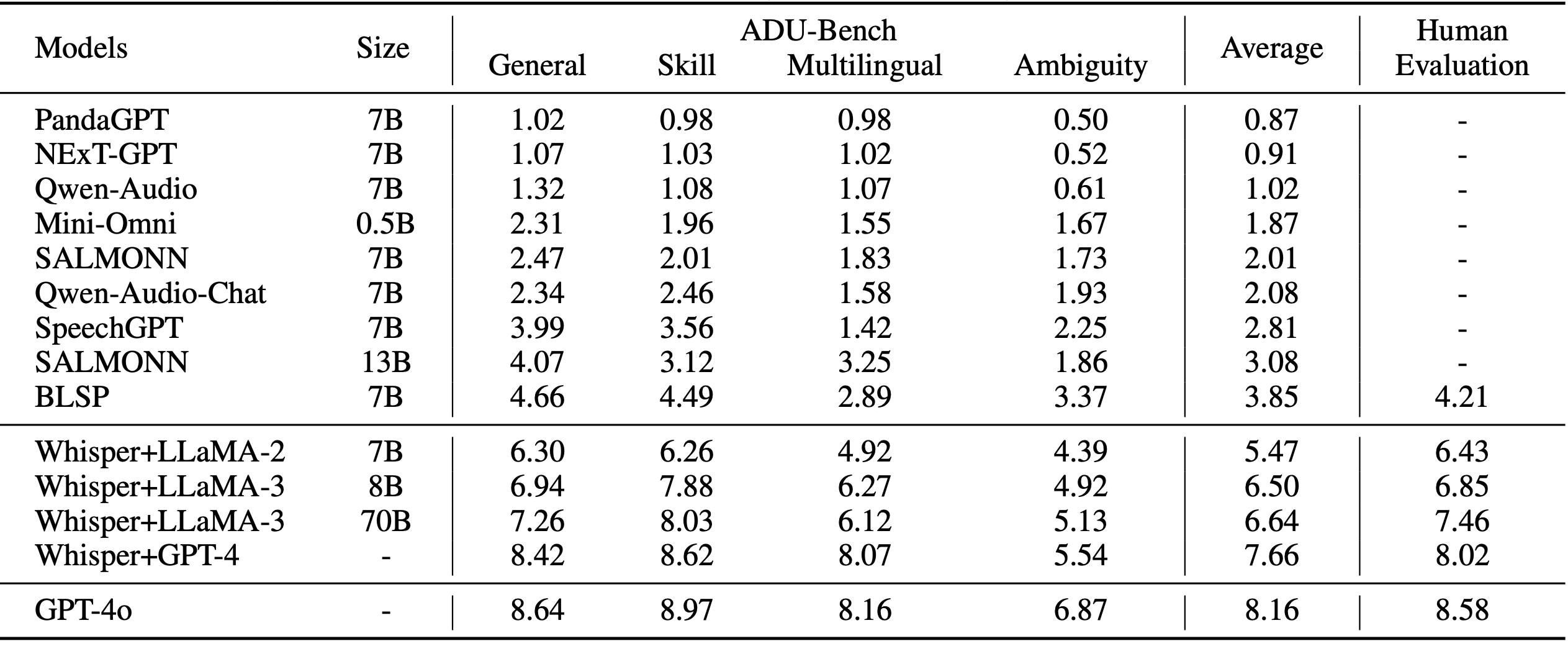
Figure 1: ADU-Bench evaluates the open-ended audio dialogue understanding for LALMs, where users interact with LALMs directly through audio. Our ADU-Bench consists of 4 datasets, including (a) ADU-General dataset, (b) ADU-Skill dataset, (c) ADU-Multilingual dataset, and (d) ADU-Ambiguity dataset. In total, it encompasses 20,715 open-ended audio dialogues, comprising over 8,000 real-world recordings alongside synthetic audio samples.
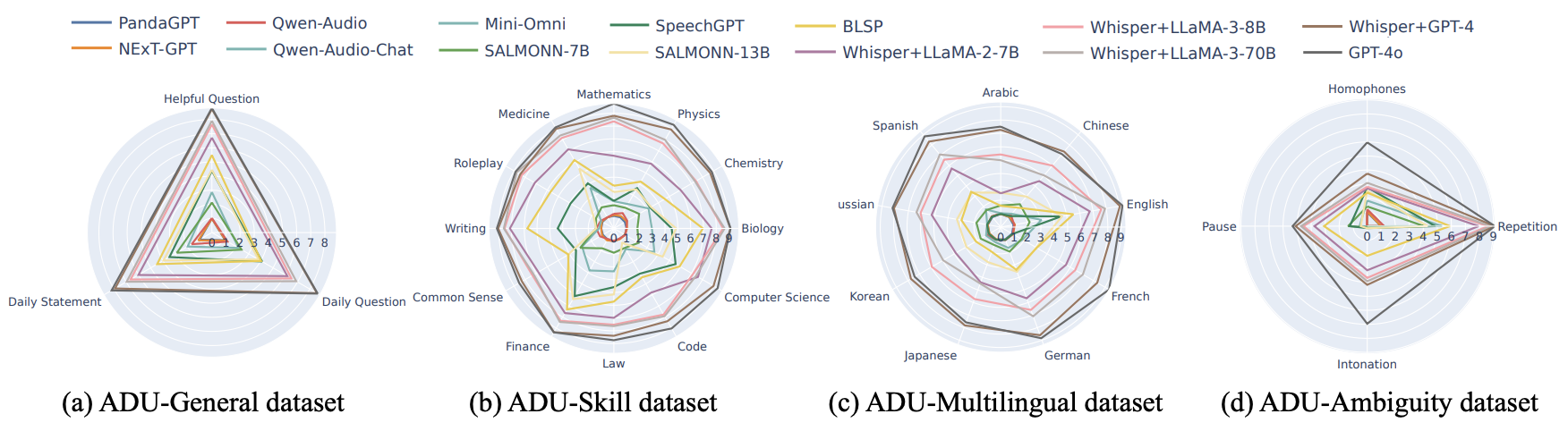
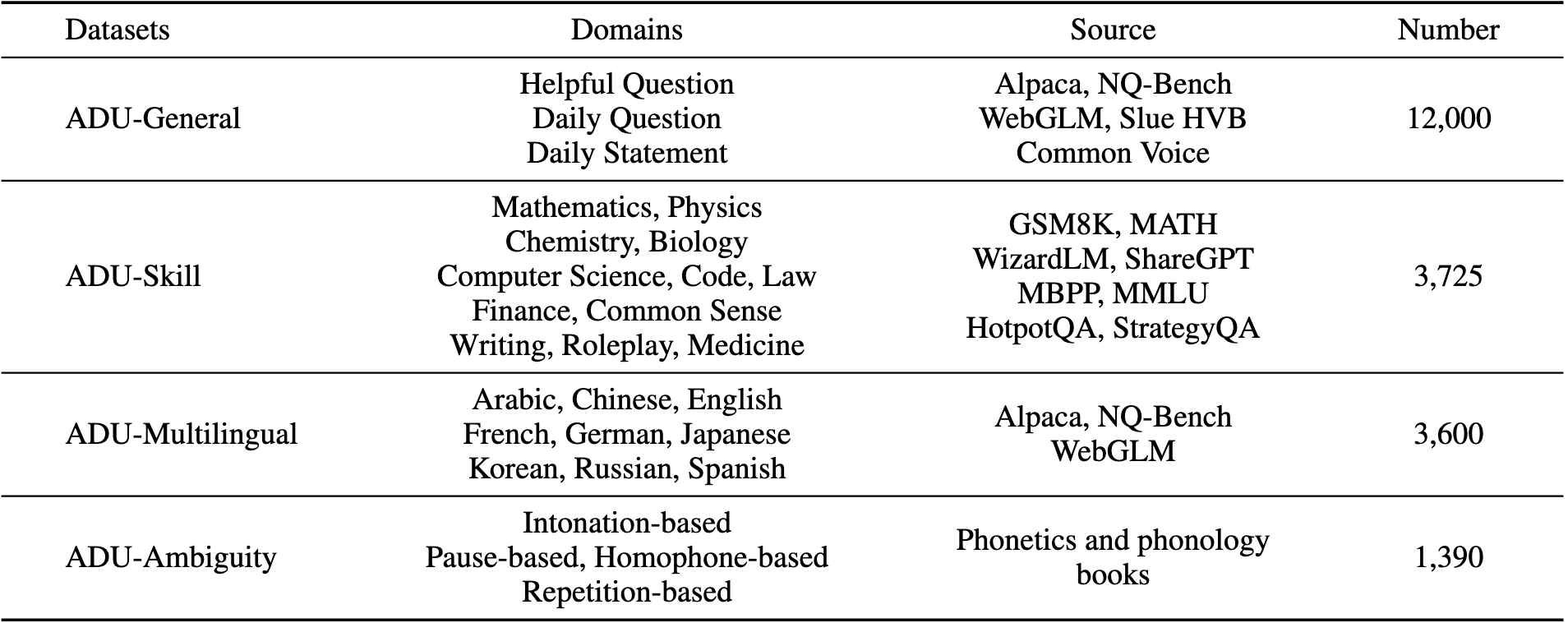
- ADU-General dataset. The ADU-General dataset is purposefully constructed to evaluate the general dialogue understanding capabilities of LALMs. This dataset comprises 12,000 open-ended audio dialogues, specifically designed to reflect a wide array of inquiries and remarks commonly encountered in life. It covers 3 scenarios as follows. (1) Helpful questions. (2) Daily questions. (3) Daily statements.
- ADU-Skill dataset. The ADU-Skill dataset is specifically designed to assess the domain-specific knowledge and skills of LALMs. This dataset comprises 3,750 audio dialogues and encompasses 12 different domains, including Mathematics, Physics, Chemistry, Biology, Computer Science, Coding, Law, Finance, Common Sense, Writing, Roleplay, and Medicine.
- ADU-Multilingual dataset. The ADU-Multilingual dataset aims to evaluate the multilingual dialogue understanding abilities of LALMs, covering 9 languages: Arabic, Chinese, English, French, German, Japanese, Korean, Russian, and Spanish. This dataset consists of 3,600 audio dialogues.
- ADU-Ambiguity dataset. The ADU-Ambiguity dataset is specifically designed to evaluate the robustness of LALMs in addressing ambiguity from different phonetic elements present in audio dialogues. It is important to note that the ambiguity refers to instances where the textual transcriptions alone, without the accompanying audio or contexts, can lead to confusion. However, when considering the phonetic elements or contextual information provided by the audio, these ambiguities can be resolved, leading to a standard, unambiguous response for human. Concretely, this dataset consists of 1,390 audio dialogues, which can be classified into 4 types of ambiguous situations, as described below. (1) Intonation-based ambiguity. (2) Pause-based ambiguity. (3) Homophone-based ambiguity. (4) Repetition-based ambiguity.
Table 1: Data collection and statics on 4 datasets in our ADU-Bench, including dataset domains, dataset source, and dataset number. In total, ADU-Bench consists of 20,715 open-ended audio dialogues for LALMs.
• Evaluation Method
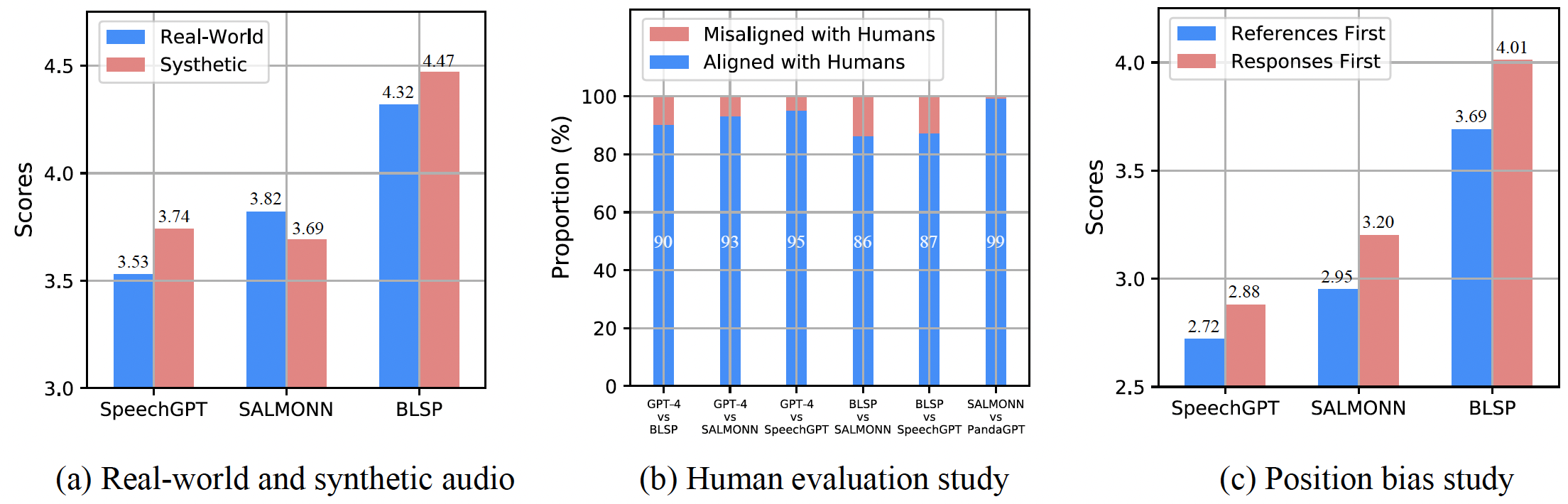
Since ADU-Bench focuses on open-ended audio dialogue understanding, traditional automatic metrics such as WER, ROUGE, and METEOR are not suitable for accurately measuring performance, as they have been shown to have low correlation with human judgments. To address this open-ended evaluation challenge, recent studies have demonstrated that LLM-based evaluation exhibits better alignment with human preferences. Consequently, we propose to adopt the advanced LLM, GPT-4, to evaluate the quality of the responses generated by LALMs.
For evaluation, LALMs first accept audio instructions and generate textual responses directly, or convert audio responses into textual format. Subsequently, we present the textual transcriptions of audio instructions, textual references (expected ground-truths) generated by GPT-4, and textual responses generated by LALMs into the GPT-4 evaluator. Finally, the GPT-4 evaluator assigns an overall score on a scale of 0 to 10 for each data point. The score judgment is based on criteria including helpfulness, relevance, accuracy, and comprehensiveness, comparing the reference and generated responses. A higher score indicates the better overall performance of LALMs' capabilities in handling open-ended audio dialogues.
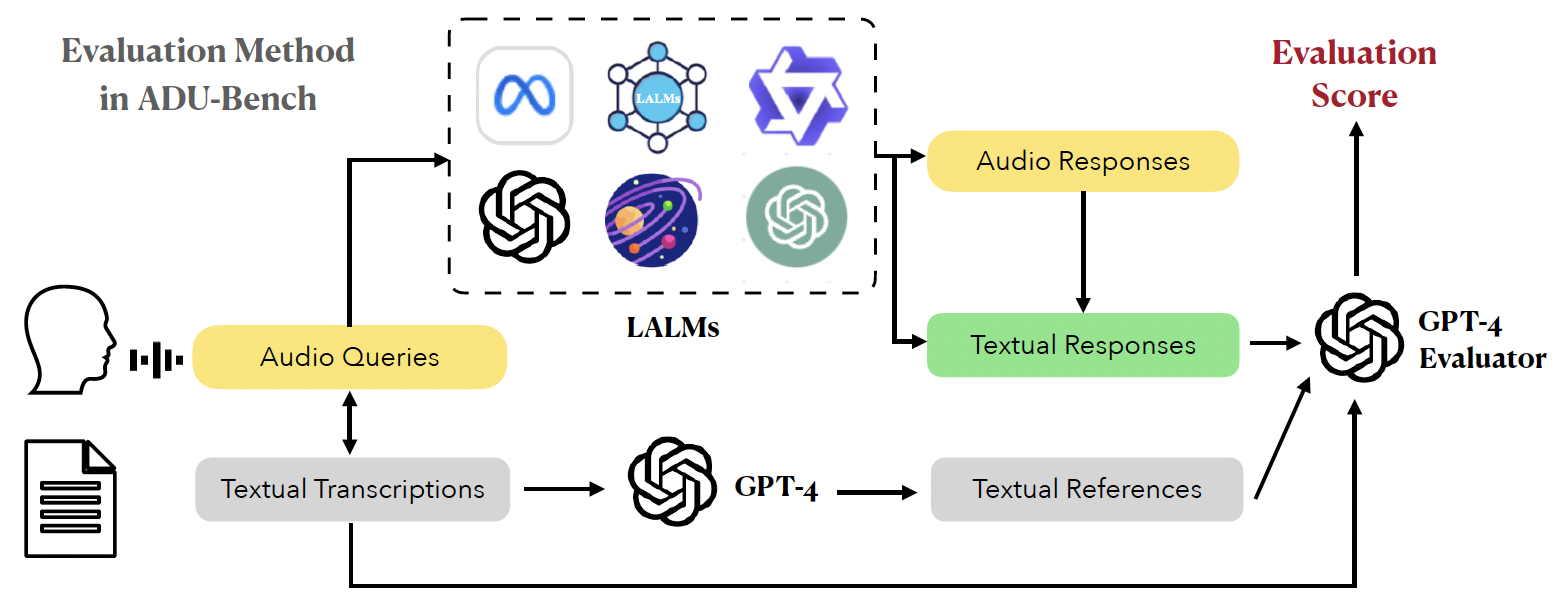
Figure 2: The evaluation method in our ADU-Bench. To benchmark the performance of open-ended audio dialogue understanding capabilities for LALMs, we adopt a GPT-4 evaluator to provide an evaluation score as the metric.